The creation of a "Namespace" that is referenced
by schema makers and schema users is done in order to distinguish
one set of element names from another set used by a different
schema. For example, the element "description" may
have divergent meanings from one set of metadata to another.
Two or more developers may be using an identical element name.
By declaring a formal Namespace in which a specific
metadata schema declares the existence and meaning of its metadata
elements and names, we avoid name collisions and confusion.
A Namespace declares a "bread crumb trail" between
real world applications of a schema's metadata and its humble origins...or
at least it points to the party responsible for its creation
in the first place. Declaring a namespace is extremely important when creating an XML Schema Document. In such documentation, it is vital to avoid collisions.
A concise discussion is available in an article from the Wikipedia, entitled XML Namespace. In a nutshell, the article states:
An XML Namespace is a W3C standard for providing uniquely named elements and attributes in an XML instance. An XML instance may contain element or attribute names from more than one XML vocabulary. If each vocabulary is given a namespace then the ambiguity between identically named elements or attributes can be resolved.
A very brief Tutorial about XML Namespaces is available from the w3schools website. One intriguing concept of XML Namespaces is as follows:
Note that the address used to identify the namespace is not used by the [XML] parser to look up information. The only purpose is to give the namespace a unique name. However, very often companies use the namespace as a pointer to a real Web page containing information about the namespace.
Try to go to http://www.w3.org/TR/html4/.
DOWNLOAD THE PBCORE XSD (XML Schema Definition)(versions 1.1 and 1.2.1):
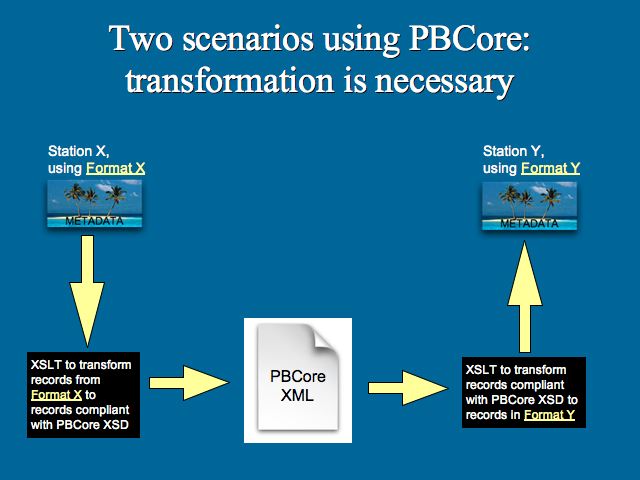
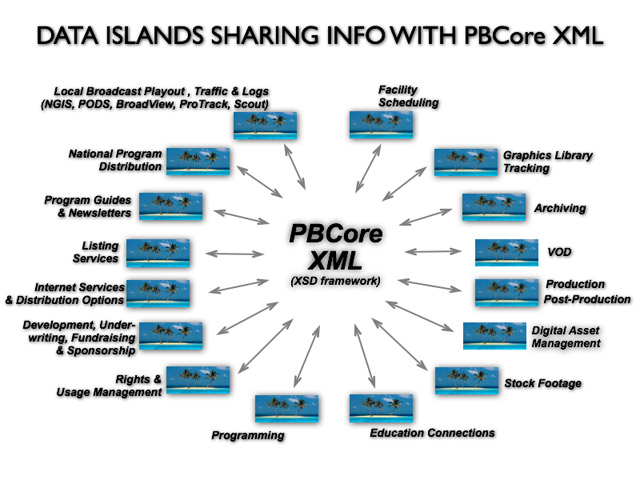
The XSD (XML Schema Definition) for the PBCore metadata dictionary is available for download. When migrating metadata from one information system (metadata island) to another system (metadata island), the PBCore XSD defines the structure and organization of the data exported from the source system. The PBCore XSD assists the information system that is importing the data by providing the consistent structure needed to re-transform the data to match that of receiving system.
As of February 2009, PBCore is publishing the next iteration of its XSD, version 1.2.1. Its predecesor, version 1.1 was made available in October of 2007. Both versions of the XSD documents are offered below. A brief explanation of the changes in PBCore v1.2.1 XSD is found in the section below under the header "PBCore Diagram--At-a-Glance."
Other Resources for Download...
PBCore Diagram -- At-a-Glance
The hierarchical branches, and leaves of the PBCore framework are alternatively expressed in our data model as "Master Container," "Content Classes,'
"Containers," "Sub-Containers," "Elements," and "Sub-Elements."
PBCore v1.1 has 53 elements, organized into 15 containers and 3 sub-containers, all grouped under 4 high level content classes.
PBCore v1.2.1 has 61 elements, organized into 15 containers and 4 sub-containers, all grouped under 4 high level content classes.
PBCore DESCRIPTION DOCUMENT (aka the MASTER CONTAINER)
The Master Container assembles together all collections of PBCore knowledge items. For PBCore these knowledge items are metadata descriptions of media. The MasterContainer is expressed as a document that hierarchically structures all the knowledge items and metadata terms and values related to a single data record associated with a media item. In our XML Schema Definition, the MasterContainer is referred to as the "PBCoreDescriptionDocument."
CONTENT CLASS (aka PBCore Section)
In the hierarchy of objects in the PBCore Description Document/Master Container, Content Classes are created as "conceptual wrappers" that cluster together a list or structure of thematically-related Elements (metadata fields and their attributes and properties). PBCore maintains four Content Classes as the conceptual wrappers for its various metadata elements:
- PBCoreIntellectualContent
Metadata elements describing the actual intellectual content of a media asset or resource.
(v1.1) 9 containers; 16 elements
(v1.2) 9 containers; 16 elements
- PBCoreIntellectualProperty
Metadata elements related to the creation, creators, usage, permissions, constraints, and use obligations associated with a media asset or resource.
(v1.1)
4 containers; 7 elements
(v1.2) 4 containers; 7 elements
- PBCoreInstantiation
Metadata elements that identify the nature of the media asset as it exists in some form or format in the physical world or digitally.
(v1.1)
1 container, 3 sub-containers; 28 elements
(v1.2) 1 container, 4 sub-containers; 36 elements
- PBCoreExtensions
Additional descriptions that have been crafted by organizations outside of the PBCore Project. These extensions fulfill the metadata requirements for these outside groups as they identify and describe their own types of media with specialized, custom terminologies unique to their needs and community requirements.
(v1.1)
1 container; 2 elements
(v1.2) 1 container; 2 elements
ELEMENT CONTAINERS & SUB-CONTAINERS (aka Schema Tag and Schema Sub-Tag, alternatively "branches"):
Elements are objects in the PBCore schema hierarchy that define a metadata field and its values, attributes and properties. An element may be standalone. If several metadata fields are thematically related to each other, they can be bound together under an Element Container. Related elements are subsumed by a larger theme, and should be bound together when data is shared (particularly if an Element Container is a repeatable description with multiple instances of its related Elements). Examples of related Elements bound within a Container are *title* and its associated *titleType*, that are bound together by the Element Container *PBCoreTitle*. Within hierarchical structures, a Container may house Sub-Containers, which themselves bind together related Elements. In PBCore, there are Sub-Containers found within the Content Class PBCoreInstantiation.
ELEMENTS (aka "leaves"):
Elements are objects that define a metadata field and its values, semantics, attributes, and properties (for a list of the attributes defined for PBCore elements, see our web page PBCore Element Attributes). An Element is the actual "thing" that carries the descriptive metadata about a media item, such as a title, a date, keywords, rights information, mime types, media types, etc. The metadata elements are what a cataloger interacts with (creating descriptions) within a cataloging tool or asset management system.
Accommodating Content Classes, Containers, and Elements, the PBCore begins to look like the diagrams below. The justification for changes to the PBCore schema from v1.1 to 1.2.1 is to better accommodate the possibility that a media asset may have multiple instantiations, all the same except for their technical attributes. Thus, metadata elements that describe the media asset as a whole still exist in v1.2.1; however, the different attributes associated with multiple instantiations are now "containerized" under a new container called the pbcoreEssenceTrack.
A somewhat dense explanation is as follows...
The recommendation for change in PBCore v1.2.1 is precipitated by difficulties in describing technical details about a media item. Specifically, and as an example, a single digital instance or rendition of a media item may have a video track, an audio track in English, an audio track in Spanish, and a captioned text track. Each track has its own unique technical specification, e.g., the video track has its own data rate, as do the audio tracks. The audio tracks also have sampling rates that are unique to digital audio, but unimportant to video tracks.
Ideally, each track of a media item can have its technical details captured by its own sub-container with its own relevant metadata elements. Thus, the creation of the sub-container pbcoreEssenceTrack within the larger parent container, pbcoreInstantiation.
A preliminary examination shows that some metadata elements are relevant for the media item essence as a whole, with all of its combined essence tracks. Other metadata elements are strictly relevant to a specific essence track. And yet others, such as data rate (and a gaggle of others), could be argued that they exist BOTH for the essence as a whole AND for specific essence tracks. Thus, metadata elements with similar meaning but differentiated by their ownership within a container or sub-container must be accommodated. These technical bits get rather complex and hierarchical in nature in order to represent them all in a meaningful way.
Indeed, pictures (in this case diagrams) are worth several hundred words. Below, click on the thumbnails for versions 1.1 and 1.2.1 to view PDF documents illustrating the differences in structure.
When the actual PBCore elements are integrated into a database and its associated cataloging application or digital asset management system, the "presentation" of the elements to the cataloger who is providing and entering metadata descriptions may not necessarily look exactly like the Hierarchy Diagram for PBCore. Often, the features and capabilities of a particular information management system require metadata elements to be displayed or function in specific ways. The actual "application" of the PBCore metadata elements may vary from the strict framework of the hierarchy or data model.
However, if metadata is to be shared, it is vital that the system's metadata is exported according to the framework of the PBCore XML Schema Definition. This export may require some transactions or transformations to be conducted on the existing metadata. But when accomplished, the exported metadata becomes a "known" and "validated" data document that a receiving information system can accurately interpret and import into its particular structures and applications.
XML transactions take place on exports from information systems. Likewise, they take place on the import of data into information systems. But at least they are conducting transactions on a commonly defined and understood XML Schema Definition.